共同能力
ASR、TTS、LLM 编排、记忆接入、角色状态层、内容状态、Action 权限、埋点日志。
本页基于新版产品方案重构技术口径:移动端房间首页承载日常在场,剧情副本承载内容演绎与关系推进,跨端生活介入承载长期陪伴和 IoT 生态联动。 核心任务不是重做数字生命底层,而是把自然交流、角色表现、内容管线、设备授权与跨端 Action 落成一套可实现、可验证、可演示、便于扩展的工程方案。
房间、剧情、跨端生活共享人格、记忆、关系与授权状态,不做割裂角色。
核心智能、关系推进和记忆读取由云端主导,本地重点负责实时表现。
先把"能说、能演、能记住"跑通,再逐步放大复杂能力。
页面主线
01 技术总览
为什么推荐
一期优先级
先做
流式 ASR / TTS、对话编排器、角色状态层、记忆调用、表情动作驱动、弱网降级。
后做
全身生成动画、复杂物理布料、端侧大模型、本地长期记忆库、动态场景生成。
ASR、TTS、LLM 编排、记忆接入、角色状态层、内容状态、Action 权限、埋点日志。
文本输入权重更高、资源预算更紧、页面与聊天容器并存、后台网络切换更频繁。
空间锚定、注视反馈、近身存在感、空间音频与性能预算比手机端更敏感。
一期做房间闭环、剧情样章和少量 IoT 联动,二期再补生态扩展、MR 高光和更重生成能力。
02 系统架构与核心模块
Architecture Map
客户端表现层 -> 交互输入层 -> 角色驱动层 -> 对话与智能层 -> 情绪与关系层 -> 记忆系统接入层 -> 内容与配置层 -> 服务端编排层 -> 数据存储层 -> 日志监控层
| 层级 | 职责 | 输入 | 输出 | 依赖 |
|---|---|---|---|---|
| 客户端表现层 | 承载 Unity 场景、角色显示、UI、音频播放、动画执行与平台适配。 | 动作指令、文本、音频流、配置、用户输入事件。 | 视觉反馈、语音输出、状态回执。 | 角色驱动层、内容配置、资源管理。 |
| 交互输入层 | 接收语音、文本、点击、凝视与打断事件,统一包装为会话输入。 | 麦克风流、文本内容、UI 事件、MR 注视事件。 | 结构化输入包。 | ASR、客户端事件系统。 |
| 角色驱动层 | 把回复语义转成表情、动作、LookAt、停顿和 Idle 行为。 | 情绪标签、动作意图、对话状态。 | Animation 指令、Blendshape 权重、注视目标。 | 对话编排器、Unity 动画系统。 |
| 对话与智能层 | 处理回复生成、追问、打断、上下文裁剪和回合推进。 | 结构化输入包、记忆召回结果、关系状态。 | 回复文本、情绪标签、行为槽位。 | LLM、编排器、记忆接入层。 |
| 情绪与关系层 | 维护情绪基线、亲密度、称呼偏好与关系推进节奏。 | 对话事件、行为事件、历史标签。 | 情绪状态、关系值、风格偏置。 | 数字生命引擎、配置层。 |
| 记忆系统接入层 | 负责记忆检索、轻量缓存、异步写回与延迟控制。 | 用户 ID、当前话题、会话意图。 | 欢迎语线索、称呼、偏好、历史片段。 | 现有记忆库 / 数字生命引擎。 |
| 内容与配置层 | 维护角色设定、提示词、情绪参数、动作映射、场景配置与灰度开关。 | 策划配置、版本信息、运营内容。 | 运行时参数与可热更新资源。 | 服务端编排层、客户端资源管理。 |
| 服务端编排层 | 统一调度 ASR、LLM、TTS、记忆检索、关系更新和日志落地。 | 会话请求、配置、服务健康状态。 | 流式 token、音频片段、行为指令、监控事件。 | 对话与智能层、数据层、监控层。 |
| 数据存储层 | 存放会话日志、关系状态、配置快照、素材元数据与监控数据。 | 结构化事件、异步写回任务。 | 查询结果、统计数据、恢复数据。 | 数据库、对象存储、缓存。 |
| 日志监控层 | 监控延迟、失败率、打断率、用户停留、ASR/TTS 质量与资源消耗。 | 埋点、错误日志、性能指标。 | 告警、仪表盘、排障线索。 | 服务端编排层、客户端埋点。 |
以下为系统最关键的 10 个模块,端云部署原则已融入表格:LLM/编排/关系/记忆/日志必须云端;动画/表情/口型/LookAt/Idle 必须本地;ASR/TTS 云端主+端侧保底;场景上下文本地采集云端使用;配置云端主+本地缓存。
| 模块 | 职责 | 部署位置 | 第一版实现深度 |
|---|---|---|---|
| ASR | 把语音流转成文本,输出时间戳和基础情绪线索。 | 云端主、端侧缓存 | 流式识别 + 中断恢复 + 关键词置信度 |
| TTS | 把回复文本转成流式语音,输出韵律控制参数。 | 云端主 | 支持情绪、停顿、语速、音色切换 |
| LLM 对话引擎 | 理解输入、生成回复、控制追问和回答风格。 | 云端 | 单角色单会话,支持文本和语音输入上下文 |
| 对话编排器 | 串起 ASR、记忆、关系、LLM、TTS 和表现指令。 | 云端 | 超时回退、流式回包、打断重入 |
| 角色意图/状态/情绪/关系 | 把回复语义归一化为行为意图,维护运行时状态、情绪基线与亲密度。 | 云端计算,客户端执行 | 规则+模型槽位输出,有限状态驱动 |
| 记忆系统接入 | 调用现有记忆库,检索与写回记忆。 | 云端 | 对话前检索、对话后异步整理 |
| 动作/表情/口型/LookAt | 选择动作、驱动面部、口型同步、稳定视线行为。 | 客户端 | 动作库+Blendshape+OVRLipSync+三级 LookAt |
| Idle 待机与手势反馈 | 无输入时保持存在感,承接低成本手势表现。 | 客户端 | 呼吸/眨眼/微转头+预设手势状态槽位 |
| 场景上下文系统 | 输入当前场景、时间、位置和交互对象。 | 客户端采集,云端使用 | 手机/MR 场景上下文统一字段 |
| 配置管理与埋点日志 | 管理提示词、关系阈值、灰度开关;记录延迟、失败、打断、停留。 | 云端主、本地缓存 / 双端 | 可版本化配置 + 客户端埋点+服务端 Trace |
03 交互链路与记忆支撑
Voice Loop
用户语音输入 -> VAD 开始录音 -> 流式 ASR -> 编排器接入场景上下文 + 关系状态 + 记忆检索 -> LLM 生成回复语义 + 情绪标签 + 行为槽位 -> TTS 流式合成 -> 客户端同步执行口型 / 表情 / LookAt / 手势 / 语音播放
这是主链路。只要这一条链路成立,项目就已经具备"自然交流 + 角色表现 + 被记住感"的基础体验。
文本输入跳过 ASR,但仍然走同一套编排、情绪、关系、记忆与表现驱动,不允许出现"文本模式只有字幕、角色没表现"的断裂。
先读取轻量记忆与关系状态;新用户走初识欢迎,老用户走差异化欢迎,客户端先进入等待与注视状态,避免空场硬切。
优先读取称呼、最近事件、当前关系阶段与上次中断话题,欢迎语、眼神和说话风格直接体现"她记得你"。
Memory Loop
对话前: 读取称呼 / 最近事件 / 关系阶段 / 近期偏好 对话中: 需要时轻量追加检索,避免每轮全量召回 对话后: 将会话摘要、关键事件、情绪波动、关系变化异步写回
05 跨端生活介入
Fensy 不能把 IoT 能力写成散落在各端的功能按钮。更稳的做法是把"提醒、播放、灯光、空气、窗帘、场景模式、车家接力"等动作抽象成统一 Action, 再由网关适配米家、Matter/HomeKit、华为鸿蒙智联、车机生态和可穿戴设备。
| 生态 / 终端 | 一期建议能力 | 接入重点 |
|---|---|---|
| 米家 / 智能家居 | 灯光、音箱、空气、窗帘、场景开关 | 优先做明确可见的环境反馈,所有执行动作必须经过用户授权和可回滚提示。 |
| Matter / HomeKit | 跨品牌设备发现、状态读取、标准化开关类动作 | 用统一设备模型屏蔽品牌差异,先支持低风险状态查询和开关类动作。 |
| 华为鸿蒙智联 | 手机、耳机、音箱、手表和家居场景联动 | 重点处理多设备连续性,让同一个角色状态能在不同终端自然接续。 |
| 车机生态 | 出行提醒、导航建议、音乐氛围、到家前场景预热 | 车机只做轻量陪伴和建议,不在驾驶过程中制造复杂交互或高风险控制。 |
| 桌面 / 耳机 / 手表 / MR | 工作陪伴、语音在场、轻提醒、高光沉浸 | 根据终端负载拆分表现层,确保同一个会话和记忆状态能跨端同步。 |
Cross-device Action Flow
用户意图 / 角色主动建议 -> 对话编排器判断场景和风险 -> Action Gateway 读取设备能力与授权策略 -> 用户确认或自动执行 -> 厂商生态适配器调用设备 -> 执行结果回写到房间、剧情关系和长期记忆
04 角色表现系统
TTS 不只是声音输出,还要同步携带语速、重音、停顿长度和情绪强度参数。 这些参数应直接影响表情幅度、头部动作频率、手势起止点和呼吸节奏。
采用"动捕 / 面捕采集 + 动画师精修 + 标准化动作库 + 条件生成模型"的路线,让 AI 生成建立在高质量基底之上,而不是从噪声数据直接黑盒出片。
每条样本都要绑定二维情绪坐标、亲密度阶段、角色状态、语义意图、语音韵律、视线目标和机位类型,保证后续模型能学到"为什么这样演"。
V1 先做"检索增强 + 条件生成 + 动作库回退"。也就是模型生成动作倾向和骨骼偏移,但关键欢迎、安抚、触碰回馈仍保留人工精选库兜底。
建议以 Russell 的环形模型作为基础理论,用效价(Valence)和唤醒度(Arousal)两个连续维度为样本打标签。采集和精修阶段都用同一套坐标逻辑,避免训练时语义漂移。
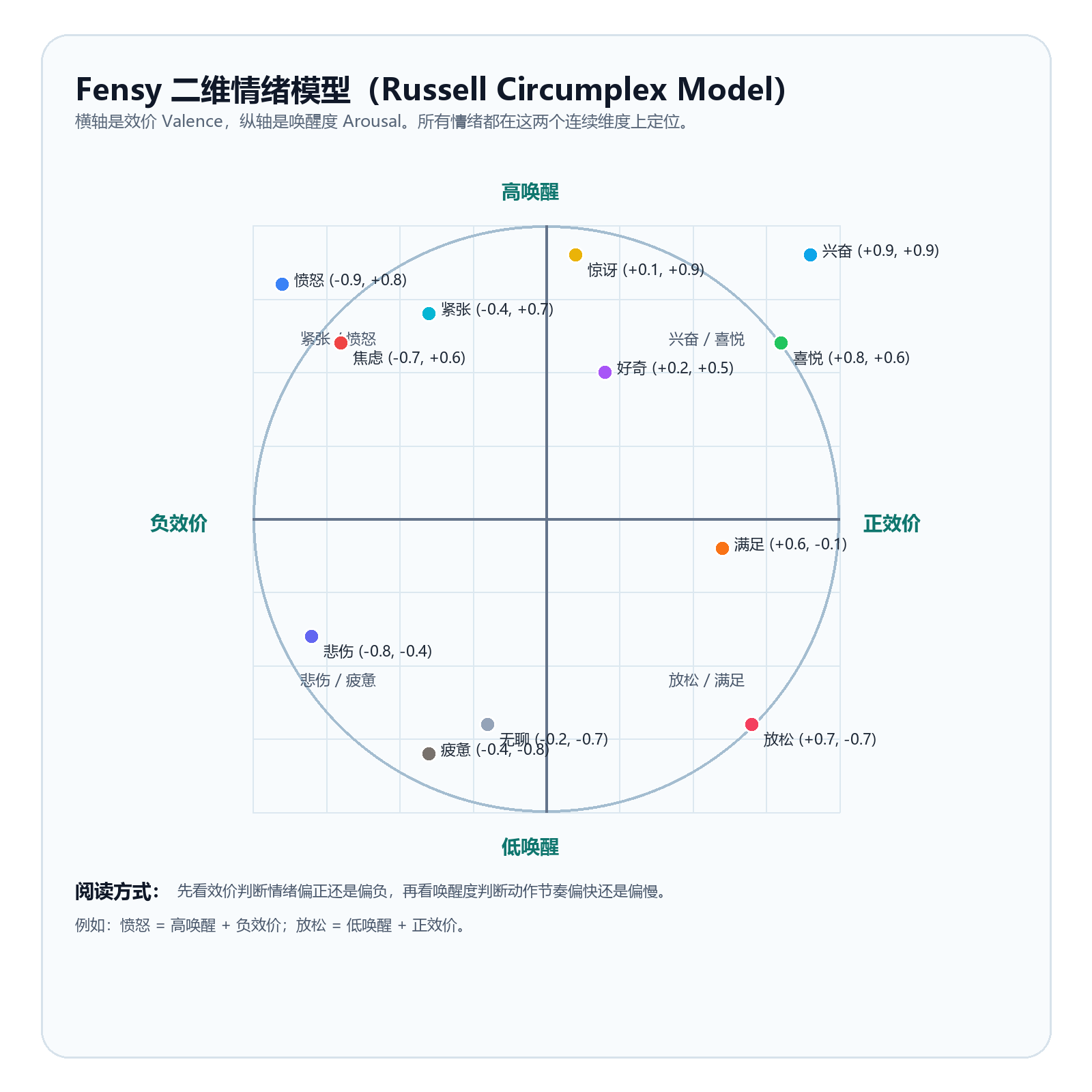
这张图可以直接作为动作生成模型、采集团队和动画师之间的统一坐标参考:先定位效价和唤醒度,再叠加亲密度、角色状态和语义意图做二级修正。
| 情绪示例 | 效价 | 唤醒度 | 二维位置理解 | 动作与表情采集重点 |
|---|---|---|---|---|
| 兴奋 | 0.9 | 0.9 | 高唤醒 + 高正效价 | 动作更快,手势外扩更明显,眉眼亮起,采集"突然点亮"和"持续兴奋"两个强度版本。 |
| 喜悦 | 0.8 | 0.6 | 中高唤醒 + 正效价 | 笑容更亮,视线更主动,头部和肩线有轻微上扬,适合欢迎和被认同时的样本。 |
| 满足 | 0.6 | -0.1 | 低唤醒 + 正效价 | 动作收稳,嘴角有轻笑,适合回复后收尾、满意陪伴和轻松确认场景。 |
| 放松 | 0.7 | -0.7 | 低唤醒 + 正效价 | 肩颈放松、呼吸变长、动作更小,重点采陪伴态、深夜安静态和无言陪伴态。 |
| 好奇 | 0.2 | 0.5 | 轻正效价 + 中高唤醒 | 头部微偏、注视更聚焦,追问意愿更明显,重点采观察、确认、被吸引的微反应。 |
| 惊讶 | 0.1 | 0.9 | 中性偏正 + 高唤醒 | 眼睛睁大、动作短促、语言滞后半拍,重点采"先反应后说话"的瞬时样本。 |
| 紧张 | -0.4 | 0.7 | 高唤醒 + 负效价 | 呼吸更短,肩颈更紧,动作更碎,重点采警觉、等待、被点名后的不稳定状态。 |
| 焦虑 | -0.7 | 0.6 | 高唤醒 + 明显负效价 | 会反复确认、目光不完全稳定,重点采担心、迟疑、难以放松的连续微动作。 |
| 愤怒 | -0.9 | 0.8 | 高唤醒 + 高负效价 | 肌肉更紧、起手更快、手势更有方向性,重点采克制型愤怒而不是夸张爆发。 |
| 悲伤 | -0.8 | -0.4 | 低唤醒 + 明显负效价 | 肩颈收束、眼神更低、语速更慢,重点采长停顿和情绪下沉时的连贯过渡。 |
| 疲惫 | -0.4 | -0.8 | 低唤醒 + 轻负效价 | 动作更慢更轻,能量感下降,适合下班、深夜、低电量陪伴等样本。 |
| 无聊 | -0.2 | -0.7 | 低唤醒 + 轻负效价 | 视线更漂移,动作更稀少,更容易出现等待和低能量停滞姿态。 |
| 亲密度阶段 | 动作倾向 | 表情与视线倾向 | 采集要点 |
|---|---|---|---|
| 初识期 0 - 20 | 动作幅度小,手势留在身体正面,不主动做高亲密接近。 | 微笑更礼貌,注视更短,疑惑和观察感更强。 | 每个情绪都要采一版"收束态",作为所有模型的安全默认值。 |
| 熟悉期 20 - 40 | 点头、回应式抬手和邀请式手势增加,节奏更稳定。 | 开始出现更自然的回看和持续倾听神情。 | 重点采日常对话、中性开心、轻度安抚等高频会话样本。 |
| 亲近期 40 - 60 | 允许轻微前倾、玩笑式摆动和共创型动作。 | 亮眼、偷笑、轻调侃表情可以更明显。 | 重点采共同兴趣、邀约、分享秘密前兆等"拉近关系"样本。 |
| 信赖期 60 - 75 | 安抚动作更慢更稳,允许长时间无动作陪伴。 | 眉眼更柔软,失落和关切之间可自然过渡。 | 重点采沉默陪伴、夜间倾听、轻度脆弱暴露等长停顿样本。 |
| 亲密期 75 - 90 | 允许回握、接物、专属仪式动作,但仍保持克制和真实。 | 害羞、安心、依恋可以复合出现,回看时间更长。 | 重点采近距离互动、触碰反馈、专属欢迎和道别等"只对你这样"的样本。 |
| 共鸣期 90 - 100 | 大动作反而减少,更依赖精确的呼吸、停顿和极小骨骼偏移。 | 一个眼神停留和一次轻呼气就要能成立,不再靠夸张演出。 | 重点采低幅度高信息量样本,让模型学会"懂你时不用演很多"。 |
| 基准 | 定位 | 优点 | 局限 | 本项目建议用法 |
|---|---|---|---|---|
| FACS / AU | 表情语义与训练标注层 | 适合描述动作单元,便于做表演语义标注和跨团队沟通。 | 不是直接的运行时 rig 标准,落到引擎还需要映射。 | 作为数据标注和动画评审语言保留,不直接作为最终面部驱动接口。 |
| ARKit Blendshape | 设备捕捉与实时驱动常用接口 | 生态成熟,移动端和实时驱动链路常见,和许多面捕工具兼容。 | 表达维度够用但不算最丰富,高质量表演仍需更细的上层控制。 | 作为设备采集与实时互通层保留,建议维护到主 rig 的双向映射。 |
| MetaHuman Facial Description Standard | 高质量数字人面部控制标准 | 语义细、覆盖广,适合高保真角色表演和后续高质量生成建模。 | 直接照搬成本较高,需要结合 Unity 运行时做资源裁剪和映射。 | 建议作为当前项目主面部基准。以它定义主 rig 与高精度语义,再导出到 Unity 运行时控制层。 |
高保真渲染
以下重点汇报角色高感知渲染的核心技术方案。我们在眼睛、面部、头发、布料和材质特效五个维度上各攻了一个关键技术难点,让水母娘在用户靠近看时,眼睛有水、脸会红、发丝会动、裙摆有重量、身体像水母一样微微发光。普通建模流程不在此赘述。

Beauty Target
第一眼要成立:温柔、湿润、会回看
水母娘不是"模型好看"这么简单,而是要让用户感觉到她是活的。我们把面部、眼睛、皮肤、头发、布料和特效绑定到同一套角色状态机里,情绪发生时,瞳孔、脸红、呼吸、发丝和裙摆会同时响应。以下五个模块各有独立的技术攻坚点,组合起来才形成了"她会看你、会害羞、会呼吸"的完整观感。
01 Eyes
眼睛要像有水、有光、有犹豫
核心难点:普通数字人眼睛像贴了一张塑料贴纸,没有深度和湿润感。真实眼球是复杂的光学系统,光线要穿透角膜、在虹膜上散射、再被泪膜折射,少了任何一层都会显得假。
我们的方案:把眼球拆成5层独立结构——巩膜(眼白)、虹膜、瞳孔、角膜、泪膜分别建模和渲染。虹膜用独立法线贴图刻画纤维放射状纹理,支持瞳孔随光线和情绪缩放;角膜设定高透射、高反射材质,叠加泪膜模拟湿润反光;巩膜区域渲染细微血管,避免眼白死白。
技术价值:多层结构让眼睛有了向内凹陷的晶体深度感,不是平面的。运行时叠加视线追踪和微扫视算法,长时间对视时她会努力看你、犹豫移开、再偷偷看回来,眼神有了"犹豫"和"害羞"的情绪温度。

02 Face
眨眼、脸红和唇部细节一起表达害羞
核心难点:标准表情系统做闭眼、大笑、嘟嘴时容易"破形"——眼皮塌陷、脸颊穿模、嘴角撕裂。情绪如果只在骨骼上切换,看起来就像换面具,没有温度。
我们的方案:在关键表情节点引入修正形变系统,闭眼时眼皮保持自然弧度、大笑时脸颊有体积、嘟嘴时嘴角不撕裂;同时保留手机面捕设备的兼容映射,采集的表演能准确还原。情绪还联动材质变化:害羞时脸颊泛红、耳尖升温、眼下色调变暖、唇部增加湿润感。
技术价值:用户看到的不是"换了个表情",而是"她真的脸红了"。近距离看也不会穿模破形,面部表演有真实肉感。
03 Hair
头发要轻、软、透,不像一整块塑料
核心难点:移动端性能有限,不能做发丝级模型,但发片如果做成死板的片状就会像塑料。高端剧情渲染又需要独立发丝的层次和光泽。头发还要能响应触碰、风力和角色动作。
我们的方案:移动端用发片方案,每束定义清晰的光泽流向和透明衰减,发梢自然虚化;刘海、鬓角、长发尾部接入弹簧骨骼链,实时计算发丝与头部运动、环境风力的物理碰撞,产生延迟摆动。高端剧情渲染切换到发束曲线模型,用大量独立发丝构建发型,体积和光泽更细腻。同一套发型资产支持分级切换。
技术价值:转头、靠近、被触碰、甚至角色呼吸时,发丝都有柔软的二级动态,不像一整块塑料。用户整理她发丝时,头发会自然受力散开再回弹。

04 Cloth
裙摆和薄纱要有重量、延迟和透明层次
核心难点:裙子、薄纱、丝带既要"版型稳定"又要"边缘会动",透明层多了还会闪烁或糊成一片。更麻烦的是,移动端算力有限,复杂物理模拟容易掉帧。
我们的方案:对腰部和肩部做固定约束,边缘设柔软约束,实时计算重力、风力、惯性以及布料与身体的碰撞,避免穿模。透明纱额外处理厚度感和边缘透光,解决多层透明旋转时的排序问题。移动端引入轻量级神经布料模型,用AI替代部分复杂物理计算,保证流畅度。
技术价值:旋转、行走、被触碰时,裙摆有自然的重量感和延迟摆动,薄纱的透明层次清晰可见。手机端也能流畅运行,高端设备效果更好。

05 Material
皮肤柔、服装精、水母元素透亮
核心难点:普通材质"死白死白",没有生命感。MR场景中,虚拟角色如果用自己的一套光照,会和真实环境割裂;水母娘的透明荧光特征,普通材质更做不出来。
我们的方案:皮肤采用次表面散射模拟光线穿透薄皮层的暖色透光,配合高分辨率纹理和多层次法线贴图还原毛孔与皱纹的微观起伏。MR端通过传感器估算真实环境光照方向和强度,让虚拟角色被同一盏灯照亮。水母特征用半透明折射、边缘荧光和噪声流动贴图,营造果冻感和深海荧光。配合接触阴影强化皮肤凹陷和物体相接处的立体感。
技术价值:角色身体本身在微微发光,有生物感。在MR里看,她像是站在你房间里,而不是一个悬浮的贴图。
核心难点:如果眼睛、面部、头发、布料、材质各自独立播放,看起来会像拼凑的动画。用户整理她发丝时,如果只有头发在动、脸没反应、眼神还盯着别处,立刻就出戏。
我们的方案:把表演拆成语义状态、面部状态、眼神状态、身体状态、材质状态、物理状态六层。用户替她整理发丝时,系统同时触发视线躲闪、眨眼变慢、脸颊泛红、发丝受力摆动、水纹从接触点扩散、裙摆轻微跟随。
技术价值:用户看到的是一个自然连续的反应,底层是六个技术层被同一事件协调。这就是水母娘"有生命感"的根本原因——她不是在"播放动画",而是在"回应你"。
皮肤次表面散射、眼睛五层结构、泪膜湿润、眨眼、微扫视和表情修正,决定用户靠近看时是否相信她是"活的"。
头发、服装、饰品、呼吸、手指和身体重心共同制造二级动态,避免角色像硬模型在播放音频。
同一套资产必须有移动端、MR、桌面和剧情渲染的质量档,靠 LOD、注视点渲染和云边协同维持稳定表现。
06 平台适配与性能保障
60fps 优先、包体与发热控制、文本输入与语音并存、断网回退、前后台状态切换更重要。
72fps 基线、空间锚定、近身表现、空间音频、视线反馈与用户舒适度控制更重要。
会话状态、记忆接入、角色状态层、表情动作映射、埋点事件、资源配置结构都应共用。
建议采用"主动作层 + 面部层 + 口型层 + 注视层"的分层结构。 这样说话时既能保持基础姿态,又能叠加口型和视线变化,不会互相覆盖。
当前目标平台不是以 Vision Pro 为首发,但 Vision Pro 平台约束仍值得保留做对照: 它对手势、空间映射、渲染管线和输入方式有更严格要求,因此本期不建议把它纳入主实现目标, 可作为后续 MR 高端平台研究项参照。
帧率、延迟、包体、成本和风险提前锁定,不让性能问题在后期爆发。
07 开发计划与选型
P0
P1
P2
P3
| 能力 | 推荐方案 | 说明 |
|---|---|---|
| 客户端引擎 | Unity 2022.3 LTS | 移动端房间与 MR 高光场景共用底座,便于角色表现复用。 |
| 动画系统 | Animator + Timeline + 事件驱动层 | 适合第一期的可控动作组织,不急于上复杂行为树。 |
| 剧情副本管线 | 关卡配置 + 视频 CDN + 立绘/语音资源包 | 把主线、支线、角色回忆和限时事件拆成可配置内容单元。 |
| ASR | Whisper 类流式方案 / 商业云 ASR | 优先稳定低延迟,后续可加端侧保底。 |
| TTS | 支持情绪参数的商业云 TTS | 先保证韵律和可控性,再做更高级定制。 |
| LLM | 云端通用多轮对话模型 | 重点看中文、多轮稳定性、工具调用能力与成本。 |
| 编排服务 | Python / FastAPI + WebSocket / SSE | 便于快速接入模型、记忆和日志链路。 |
| 记忆接入 | 复用现有记忆库 / 数字生命引擎 | 本任务明确不重构,而是做稳定接入。 |
| IoT 接入 | Action Gateway + 厂商生态适配器 | 优先支持米家、Matter/HomeKit、鸿蒙智联、车机生态的低风险动作。 |
| 日志监控 | 结构化埋点 + 服务端 Trace | 至少要能回放单次会话的关键链路。 |